Esta sección presenta los resultados de los análisis utilizando la metodología propuesta en un conjunto de datos reales y los compara con las alternativas más populares. El rendimiento del método también se estudia mediante un estudio de simulación integral, con y sin covariables.
En este apartado se estudia el funcionamiento y aplicación de la metodología propuesta mediante un completo estudio de simulación y un conjunto de datos reales sobre la incidencia del Covid-19 en España.
Estudio de simulación
Aunque el método de estimación ya se conoce y se ha probado anteriormente, hasta donde sabemos, nunca se ha utilizado en el contexto de series temporales ARCH y, por lo tanto, se realizó un estudio de simulación exhaustivo para garantizar que el modelo se comporte como se esperaba, incluido \ (soporte \ izquierda (1 \ derecha) \)Y \(AR \izquierda (1 \derecha)\)Y \(MA \izquierda (1 \derecha)\) Y \(ARMA \izquierda (\mathrm {1,1} \derecha)\) Estructuras para el proceso oculto \({X}_{t}\) niño
$$\start{matriz}{c}{X}_{t}={\phi }_{0}+{\phi }_{1}\cdot {X}_{t-1}+{Z} _{t},{Z}_{t}^{2}={\alfa}_{0}+{\alfa}_{1}\cdot {Z}_{t-1}^{2}+ {\epsilon }_{t}\text{(ARCH(1))}\\{X}_{t}={\phi }_{0}+\alpha \cdot {X}_{t-1} +{\epsilon }_{t}\text{(AR(1))}\\{X}_{t}={\phi }_{0}+\theta \cdot {\epsilon }_{t- 1} + {\epsilon }_{t}\text{(MA (1))}\\{X}_{t}={\phi }_{0}+\alpha \cdot {X}_{t -1}+\theta \cdot{\epsilon }_{t-1}+{\epsilon }_{t}\text{(ARMA (1, 1))}\end{matriz}$$
(4)
dónde \({\epsilon }_{t}\sim N\left({\mu }_{\epsilon } \left(t \right),{\sigma }_{\epsilon }^{2} \right)\ ).
Valores paramétricos \({\fi}_{1}\)Y \({\alfa}_{0}\)Y \({\alfa}_{1}\)Y \(\alfa\)Y \(\theta\)Y \(q\) Y \(\omega\) Osciló entre 0,1 y 0,9 para cada parámetro. El sesgo absoluto medio, la duración media del intervalo (AIL) y la cobertura media del intervalo creíble del 95 % se muestran en la Tabla 1. Para resumir el poder del modelo, estos valores se promedian sobre todas las combinaciones de parámetros, teniendo en cuenta que su anterior la distribución es un delta de Dirac con todas las probabilidades concentradas en el valor del parámetro correspondiente.
Para cada estructura de autocorrelación y conjunto de parámetros, una muestra aleatoria de tamaño \(n = 1000\) Creado con la función R. arima.simy parámetros \(m=registro\izquierda ({M}^{*}\derecha)\) Y \(\beta\) se ha fijado en \(0.2\) Y \(0.4\) respectivamente. Se tuvieron en cuenta varios valores para estos parámetros, pero no se observaron diferencias significativas en el rendimiento del modelo con respecto al valor de estos parámetros o el tamaño de la muestra, así como una menor cobertura para tamaños de muestra más bajos, como se esperaba.
La incidencia real del Covid-19 en España
El virus betacoronavirus SARS-CoV-2 ha sido identificado como el agente causal de un brote global de neumonía sin precedentes que comenzó en diciembre de 2019 en Wuhan (China) [1], llamado Covid-19. Dado que muchos casos cursan sin síntomas o con síntomas muy leves, es razonable suponer que la incidencia de esta enfermedad no está suficientemente registrada. Este trabajo se centra en la incidencia semanal de Covid-19 registrada en España en el periodo (23/02/2020 – 27/02/2022). Se puede ver en la Figura 1 que los datos registrados (turquesa) solo reflejan una fracción de la incidencia real (rojo). El área gris corresponde al 95 % de probabilidad de la distribución post hoc del número semanal de casos nuevos (los límites inferior y superior de esta área representan los percentiles 2,5 % y 97,5 %, respectivamente), y la línea punteada roja corresponde a su significar.
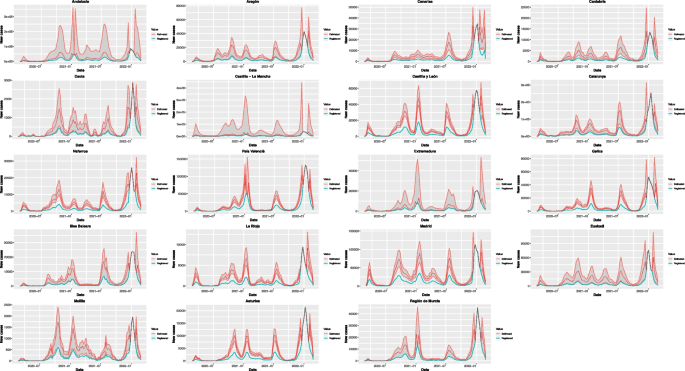
Registrar y pronosticar semanalmente nuevos casos de Covid-19 en cada región española
En el periodo estudiado, las fuentes oficiales reportan 11.056.797 casos de Covid-19 en España, mientras que el modelo predice un total de 21.639.627 casos (solo se reportan el 51,10% de los casos reales). Este trabajo también mostró que si bien la frecuencia de subregistro es muy alta para todas las regiones (valores para \(\ancho {\omega}\) superior a 0,80 en todos los casos), la gravedad de este subregistro no es uniforme entre las regiones estudiadas: Aragón y Ceuta son las dos CCAA con mayor intensidad notificada (\(\ancho {q}=0.28\)) mientras que la Región de Murcia y el País Valencià son las regiones donde los valores predichos se acercan más al número de casos notificados (\(\ancho{q}=0.46\)). Las estimaciones de los parámetros de no notificación detallados para cada región se pueden encontrar en la Tabla 2. Aunque el efecto principal de los programas de vacunación se puede ver en los datos de mortalidad, los resultados de este trabajo también mostraron una disminución significativa en el número semanal de casos. como en todas las CCA. A excepción de Euskadi, como también se puede observar en la Tabla 2 por las correspondientes estimaciones del parámetro \({\beta}_{2}\). La Figura 2 representa la incidencia semanal prevista y registrada de Covid-19 a nivel mundial en España.
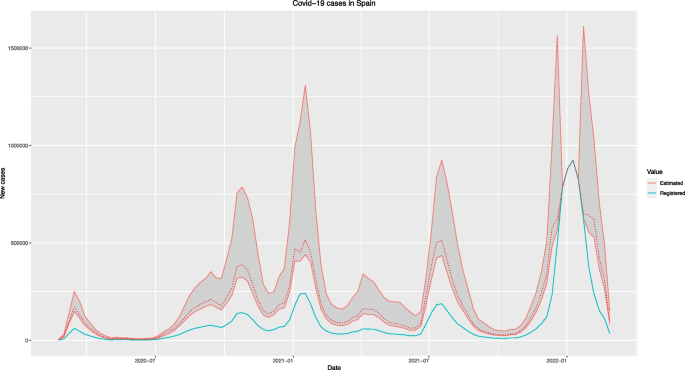
Registro y previsión semanal de nuevos casos de Covid-19 a nivel mundial en España
La figura 2 muestra la evolución del número semanal registrado (turquesa) y proyectado (rojo) de casos de Covid-19 en España en el periodo 23/02/2020–27/02/2022.
Como puede verse en la fig. 1 y 2, hay 4 semanas (2021-12-26, 2022-01-02, 2022-01-09 y 2022-01-16) cuyos valores previstos coinciden con los registrados en todas las simulaciones, por lo que no hay subregistro que descubrí estas semanas. Este comportamiento puede haber sido el resultado de un brote de una nueva variante con características diferentes (p. ej., que produce más casos sintomáticos y, por lo tanto, menos subregistro) alrededor de estas fechas.
Los valores registrados predichos por el modelo también se pueden obtener en forma de \(\widehat {Y_t} = \left (1- \widehat \omega + \widehat \omega \cdot \widehat q \right) \cdot \widehat {X_t}\)y en comparación con los valores reales registrados \({Y}_{t}\). Esto permite el cálculo de medidas estándar de errores de predicción, como el error cuadrático medio (RMSE) o el error porcentual absoluto medio (MAPE). A nivel mundial, el RMSE fue de 113.145,4 y el MAPE fue de alrededor del 8 %, con un rango del 4 al 13 % en todas las regiones. El RMSE y MAPE específicos para cada región se describen en la Tabla S1 en el Material complementario.
Las diferencias globales en las magnitudes de subregistro entre regiones se pueden representar mediante el porcentaje de casos notificados en cada CCAA (en comparación con las estimaciones del modelo), como se muestra en la Figura 3.
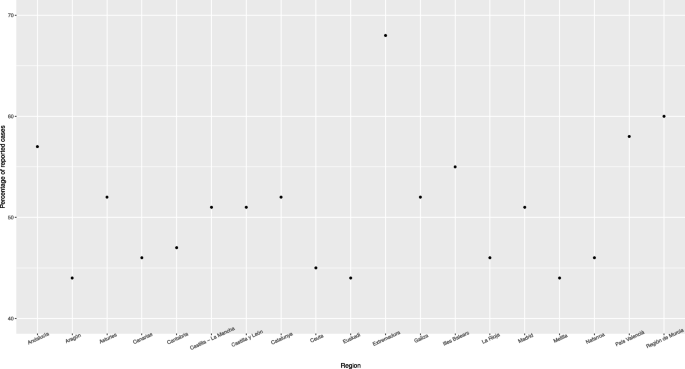
Porcentaje de casos notificados en cada CCAA

«Solucionador de problemas. Gurú de los zombis. Entusiasta de Internet. Defensor de los viajes sin disculpas. Organizador. Lector. Aficionado al alcohol».